
今回構築する環境と必要なモノ
構築手順の確認と検証のためとなるので、下記が必要なものとなります。
・ESXi
・Ubuntu
これだけですね。
ESXiに3つの仮想マシンを作成します。
それらは全てUbuntu。
ひとつがコントロールプレーンと呼ばれるMasterノード。
他2つがWorkerノードとなります。
ESXi:仮想マシン(Ubuntu)の用意
とにもかくにもESXi上に仮想マシンとしてUbuntuを乗せる
Ubuntuのインストール過程は省略。
インストールには多少の時間がかかるので、3台を一度に作成してインストールを開始させてしばらく放置。(とはいえ、サーバがTM200でもそんなに時間はかからなかったかな)
<注意事項>
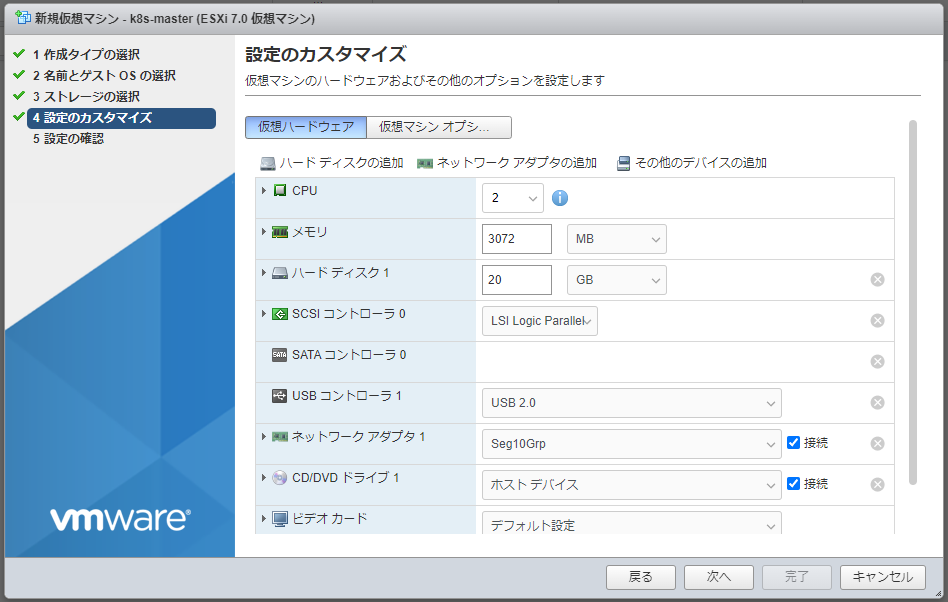
・vCPUは2以上
・メモリは2GB以上
ここはデフォルトから手動で変更しないと下回ってるので要変更。
しかもメモリ2GBはアプリが使える領域がほとんどないそうなので、少し増やしておくと良いかも。
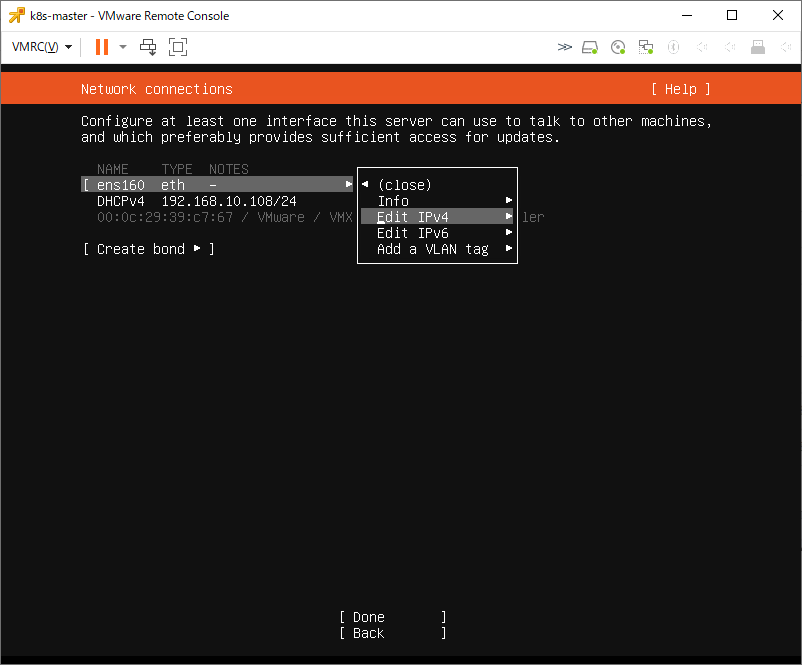
また、Ubuntuインストール中にネットワーク設定でDHCPからManualに変更してIPを固定しよう。
全てのUbuntu:全ノードで共通の作業
iptablesの設定
参考URL:https://kubernetes.io/ja/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
br_netfilter モジュールがロードされているか確認。
ついでにoverlayについても見ておく。
$ sudo lsmod | grep br_netfilter
$ sudo lsmod | grep overlayうちはロードされていなかったので、下記のようにしてロードしておく。
$ sudo modprobe br_netfilter
$ sudo modprobe overlay続いて /etc/sysctl.d/k8s.conf ファイルを作成し、内容を下記の通りに。
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1/etc/modules-load.d/modules.conf も下記の2分を追加する。
overlay
br_netfilter編集が終わったら、構成ファイルを反映させる。
$ sudo sysctl --system今回使用したUbuntuでは問題なかったけど、iptables が nftables API を使う iptables-nft に設定されているとDockerが外部と通信出来ないので、iptables-legacy になっているか確認。
ls -al /etc/alternatives/iptables
lrwxrwxrwx 1 root root 25 Feb 23 08:55 /etc/alternatives/iptables -> /usr/sbin/iptables-legacyもし、legacy になっていなかったら、下記のコマンドを打って、legacy となっている番号を選び、変更しておく。
$ sudo update-alternatives --config iptables
There are 2 choices for the alternative iptables (providing /usr/sbin/iptables).
Selection Path Priority Status
------------------------------------------------------------
* 0 /usr/sbin/iptables-legacy 20 auto mode
1 /usr/sbin/iptables-legacy 20 manual mode
2 /usr/sbin/iptables-nft 10 manual mode
Press <Enter> to keep the current choice[*], or type selection number:
入ってなかったパッケージのインストール
$ sudo apt install apt-transport-httpsDockerのインストールと設定の変更、サービスの有効化
Dockerのインストール
$ sudo apt install docker.io設定ファイルの変更。
/etc/systemd/system/multi-user.target.wants/docker.service
このファイルの「ExecStart」の末尾に「–exec-opt native.cgroupdriver=systemd」を追加。
(Dockerがsystemdを使うようにしないとダメらしい。最初、これでハマった・・・)
<修正前>
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock
<修正後>
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock --exec-opt native.cgroupdriver=systemdDockerサービスの有効化(サーバ再起動時にDockerサービスが自動的に起動するようにする)
$ sudo systemctl enable docker.serviceその他、チョイチョイ設定
Kubernetesのリポジトリ キーを取得して追加。
$ curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key addKubernetesリポジトリを追加。
$ sudo apt-add-repository "deb http://apt.kubernetes.io/ kubernetes-xenial main"swapの無効化
いろいろなサイトに下記コマンドを打つよう記載があるけど、これ意味なくね?
だって、一時的な変更で、サーバー再起動でまた有効になるから・・・
swapoff -aなので、/etc/fstab を編集するべきでしょう。
このファイルの最後の方にあるswapに関する記述を#でコメントアウト。
#/swap.img none swap sw 0 0サーバの再起動
$ sudo rebootkubernetes のインストール
kubelet はMasterサーバだけで良い?という記載もどこかで見かけたけど、とりあえず、全ノードにインストールする。
$ sudo apt install kubeadm kubectl kubeletMasterノードでの作業:kubernetes クラスタ構築
Kubernetesクラスタの初期化
「kubeadm init」といったコマンドを打つけど、その際に「kubeadm config images pull」もやってね、というメッセージが出ていたので、予め実行しておく。
$ sudo kubeadm config images pull続いてkubernetesクラスタの初期化。
–node-name は不要かも知れないけど、自ホスト名を明示した。
–apiserver-advertise-address は複数NICを持っているなら書かなきゃダメ。
–pod-network-cidr は後でflannelというネットワークプラグインを使うためのアドレス
$ sudo kubeadm init --node-name k8s-master --apiserver-advertise-address=192.168.1.1 --pod-network-cidr=10.244.0.0/16しばらく待つと・・・
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.1.1:6443 --token oviwhw.tj7hsu26h6hdjnd7 \
--discovery-token-ca-cert-hash sha256:9ac9be65d23342b4296f940e4d4cb709677a43b184b5300c7404c7ddd3a132a9「Your Kubernetes control-plane has initialized successfully!」
という表示が現れれば、初期化に成功。
ここまでがけっこう大変かも。
その後は、メッセージに指示されている通り、下記コマンドを実行。
$ mkdir -p $HOME/.kube
$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
$ export KUBECONFIG=$HOME/.kube/config同様にPOD に必要なネットワーク構成をインストール。
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml上手く初期化が行えない場合、
どこかで設定を間違えたか何か作業が抜けているはず。
それらを見直してもう一度「kubeadm init」をするわけだけど、その前にはリセットした方がいい。
# sudo kubeadm resetんで、その見直した方がいい、という箇所。
ip link で flannel.1 といったNICが残っていたら ip link delete flannel.1 で削除する。
同じくcni0 も削除。
また、/etc/cni/net.d/ 内のファイルも全て削除する。
$home/.kube/config これも削除。
Masterノードのステータス確認
ここまで来れば、Masterノードがきちんと動作しているはず・・・
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane,master 4m v1.23.4STATUSがReadyになっているのでOKですね。
Workerノードでの作業:kubernetes クラスタ構築(クラスタへの参加)
Workerノードの追加
Masterノードで「kubeadm init」を実行した際、
Then you can join any number of worker nodes by running the following on each as root:
というメッセージに続くコマンドがあった。
これがWorkerノードを追加するコマンドなので、それをWorkerノードで実行する。
$ sudo kubeadm join 192.168.1.1:6443 --token [ここにtokenを入力] --discovery-token-ca-cert-hash sha256:[ここにhashを入力]ちょっぴし待つと・・・
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.と表示されてクラスタへ参加出来たことがわかる。
Run ‘kubectl get nodes’ on the control-plane to see this node join the cluster.
という表示もあるので、Masterノード(control-plane)でも確認してみる。
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane,master 14m v1.23.4
k8s-worker1 NotReady <none> 17s v1.23.4NotReadyになっているのはネットワークプラグイン(flannel)のインストールを忘れてたから・・・
2台目のWorkerノードも同様にしてクラスタへ参加させる。
(この時はネットワークプラグインのインストールを済ませた)
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane,master 27m v1.23.4
k8s-worker1 Ready <none> 30m v1.23.4
k8s-worker2 NotReady <none> 10s v1.23.4worker1がReadyなのに対してworker2がNotReadyなのはkubectlが早すぎたから。
1分ほど待ってもう一度実行すると無事worker2もReadyになりましたとさ。
Workerノードが追加出来ないとき
iptablesで6443ポートが開放されていない。
iptablesの設定が難解だから、ということでufwを有効化していると見落としがち。
sudo ufw allow 6443 でポートを開放してあげよう。
tokenは24時間でなくなる
クラスタ構築が完了し、後日、ノードを追加したい場合、「kubeadm join」を行うけれど、tokenは24時間で無効になる。
なので、tokenを再作成しなければならない。
が、まずはtokenが生きているか確認。
$ kubeadm token listtokenが表示されればまだ使える。
TTLで寿命がわかるので、確認しておこう。
もし何も表示されず、tokenがなくなっていたら下記のようにして再作成。
$ sudo kubeadm token createhashは下記のようにして確認。
$ openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'これでいつでも参加出来るようになりました。
Podを作成してコンテナを実行する
現在の状況を確認してみる。
$ kubectl get pods
No resources found in default namespace.まだ何も作ってないので空っぽ。
みんなが試すnginx。
yamlファイルを下記のように書いてみる。
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- image: nginx:1.13
name: nginx
- containerPort: 80そして、kubectl でデプロイ。
kubectl apply -f nginx.yaml正常にデプロイされたか確認。
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx 0/1 Running 0 1m4sSTATUS が Running となっているのでとりあえずはOK。
よく使うコマンド
全てのpodの状態を見る
$ kubectl get pods --all-namespaces全てのpodのログを見る
$ kubectl describe pods --all-namespaces
この記事にコメントしてみる